구글이 정말 무너지고 있을까요? 점유율 하락이라는 숫자 뒤에 숨겨진 거대한 반격의 서막과, AI 전쟁의 판도를 뒤집을 구글만의 독창적인 기술력을 심층 분석합니다.
👑 구글 멸망론이 시기상조인 이유: 왕의 귀환을 준비하는 3가지 비밀 무기
"구글, 이제 끝난 거 아니야?"
최근 기술 뉴스란을 뜨겁게 달군 헤드라인 기억하시나요? "구글 검색 점유율 90% 붕괴". 이 문구 하나에 많은 사람들이 구글의 시대가 저물었다고 속단했습니다. 일론 머스크는 AI가 검색을 대체할 것이라 호언장담했고, 심지어 엔비디아의 젠슨 황조차 구글 대신 '퍼플렉시티(Perplexity)'를 사용한다고 밝혔죠.
우리가 매일 쓰는 스마트폰 화면 속, 링크만 나열해 주는 구글의 모습은 챗GPT가 주는 명쾌한 답변에 비해 마치 늙고 지친 공룡처럼 보였을지도 모릅니다. 하지만 여러분, 보이는 것이 전부는 아닙니다. 우리가 "구글의 몰락"을 이야기하는 이 순간에도, 구글의 데이터센터 가장 깊은 곳, 그 심연(Abyss)에서는 물리 법칙을 거스르는 우아하고도 치명적인 반격이 준비되고 있습니다.
겉으로 드러난 점유율 하락은 수면 위의 작은 얼음 조각일 뿐입니다. 수면 아래에는 압도적인 하드웨어, 혁명적인 알고리즘, 그리고 타의 추종을 불허하는 데이터라는 거대한 본체가 숨겨져 있습니다. 왜 구글의 위기가 단순한 '착시'에 불과한지, 그들이 숨겨둔 고귀한 승부수는 무엇인지 그 비밀의 문을 열어보겠습니다.
👑 1. 하드웨어의 반란: 왜 구글은 엔비디아를 쓰지 않는가?
AI 전쟁은 곧 '칩(Chip)' 전쟁이라고 해도 과언이 아닙니다. 현재 전 세계 거의 모든 테크 기업은 엔비디아의 GPU를 구하기 위해 천문학적인 돈을 싸 들고 줄을 서고 있습니다. 하지만 구글은 다릅니다. 그들은 남들이 가는 길을 거부하고, 자신들만의 독창적인 길을 개척했습니다.
💡 GPU는 'SUV', TPU는 'F1 레이싱카'
엔비디아의 GPU는 분명 훌륭합니다. 게임도 하고, 그래픽 작업도 하고, 코인 채굴도 하고, AI도 돌립니다. 마치 비포장도로와 고속도로를 모두 달릴 수 있는 최고급 SUV와 같습니다. 범용성이 뛰어나죠.

하지만 AI 연산, 특히 검색 엔진을 돌리는 데 필요한 연산의 99%는 단순한 ‘행렬 곱셈(Matrix Multiplication)’입니다. 구글은 여기서 아주 본질적인 질문을 던졌습니다.
*"이것저것 다 하는 칩 말고, 오로지 행렬 곱셈만 미친 듯이 잘하는 칩을 만들면 어떨까?"*
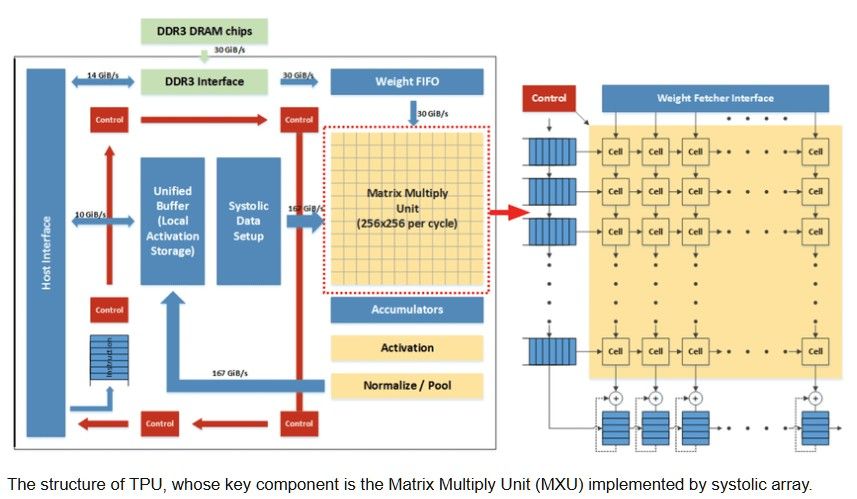
그 결과물이 바로 TPU(Tensor Processing Unit)입니다.
- GPU (SUV): 다양한 기능을 수행하기 위해 구조가 복잡하고 전기를 많이 먹습니다.
- TPU (F1 레이싱카): 불필요한 기능은 싹 걷어내고, 오직 AI 연산 효율만 극한으로 끌어올렸습니다.
구글의 TPU는 좁은 서킷(AI 연산) 위에서는 그 누구도 따라올 수 없는 속도를 자랑합니다. 이 덕분에 구글은 경쟁사보다 훨씬 적은 전력과 비용으로 거대 AI를 구동할 수 있는 것입니다.
📌 데이터의 심장 박동, 시스톨릭 배열(Systolic Array)
TPU의 핵심 비밀은 ‘시스톨릭 배열’이라는 아키텍처에 있습니다. 이름이 조금 어렵죠? 의학 용어인 '수축기(Systolic)'에서 따온 말인데, 심장이 피를 펌프질하는 원리와 같습니다.

기존 GPU 방식은 데이터를 계산할 때마다 창고(메모리)에서 숫자를 꺼내오고, 계산하고, 다시 넣는 과정을 반복합니다. 이를 '메모리 병목'이라고 하며, 여기서 엄청난 시간과 에너지가 낭비됩니다.
반면, TPU의 시스톨릭 배열은 데이터가 칩 내부를 물결처럼 흐르게 만듭니다.
- 데이터가 첫 번째 연산 유닛에 들어갑니다.
- 계산된 결과와 데이터가 바로 옆, 혹은 아래의 유닛으로 전달됩니다.
- 창고(메모리)에 왔다 갔다 할 필요 없이, 칩 내부에서 모든 계산이 끝날 때까지 데이터가 재사용됩니다.
이 기술 덕분에 구글은 AI 검색 비용을 획기적으로 낮출 수 있었습니다. 최근 OpenAI조차 구글의 TPU 성능을 탐낼 정도로, 이 기술 격차는 실로 거대합니다.
👑 2. 속도 혁명: '타자기'를 버리고 '판화'를 찍다
하드웨어가 튼튼한 '몸'이라면, 그 위에서 돌아가는 알고리즘은 '뇌'입니다. 구글은 현재 우리가 쓰는 AI 챗봇의 가장 큰 불만 사항인 '느린 속도'를 극복할 새로운 무기를 꺼내 들었습니다.
⚠️ 타자기 치는 AI (Autoregressive Model)의 한계
지금의 챗GPT나 제미나이 초기 모델은 '자기회귀(Autoregressive)' 방식을 씁니다.

“안녕” ⇒ "하세요" ⇒ "저는"…
앞 단어가 나와야만 뒷 단어를 예측할 수 있습니다. 마치 타자기로 한 글자씩 치는 것과 같죠. 문장이 길어질수록 시간은 정직하게 늘어납니다. 한국인처럼 "빨리빨리"를 좋아하는 사용자들에게, 검색 결과가 1초라도 늦게 나오는 건 참을 수 없는 일입니다.
💡 7배 빠른 미래, MDLM (디퓨전 언어 모델)
구글 리서치 팀은 이미지 생성 AI(미드저니 등)에서 영감을 얻어 MDLM(Masked Diffusion Language Model)을 개발했습니다. 이 모델은 글을 쓰는 방식이 완전히 다릅니다.

- 가리기 (Masking): 문장의 여러 곳을 잉크로 가려버립니다.
- 동시 복원: AI가 앞뒤 문맥을 동시에 고려하여, 가려진 빈칸을 한꺼번에 채워 넣습니다.
타자기로 한 자 한 자 치던 글을, 이제는 ‘판화’처럼 한 번에 쾅! 하고 찍어내는 것입니다. 초기 실험 결과, 이 방식은 기존보다 7배 이상 빠른 속도를 보여주었습니다. 구글 검색창에 질문을 던지는 순간, 로딩 바 따위는 없이 완성된 답변이 0.1초 만에 뜨는 세상. 이것이 구글이 준비하는 'Gemini 2.5' 이후의 미래입니다.
👑 3. 규모의 경제: 137억 건의 데이터와 무료의 힘
기술이 아무리 좋아도, 결국 AI를 똑똑하게 만드는 건 데이터입니다. 여기서 구글은 스타트업들이 넘볼 수 없는, 마치 성벽과도 같은 '통곡의 벽'을 가지고 있습니다.
📌 롱테일(Long Tail)의 지배자
- Perplexity: 월 7억 8천만 건 처리
- Google: 일 137억 건 처리
단순히 양만 많은 것이 아닙니다. "오늘 날씨" 같은 흔한 질문은 누구나 답할 수 있습니다. 문제는 희귀하고 구체적인 질문입니다.

*"2004년식 혼다 시빅 라디에이터에서 비 오는 날만 나는 소음 원인은?"*
이런 질문을 롱테일 키워드라고 합니다. 데이터가 부족한 AI는 이런 질문에 그럴싸한 거짓말(환각)을 내놓기 쉽습니다. 하지만 구글은 지난 25년간 전 세계 80억 인구가 남긴 수조 개의 희귀한 검색 기록을 보유하고 있습니다. 이 '데이터의 깊이'가 곧 AI의 지능 차이를 만듭니다.

💡 치킨 게임의 승자: 1달러당 지능
현재 AI 검색 스타트업들은 투자금을 태우며 적자를 감수하고 있습니다. GPU 비용이 워낙 비싸기 때문이죠. 하지만 구글은 압도적인 광고 수익과 앞서 말한 TPU의 효율성을 바탕으로 ‘가장 저렴하게 지능을 생산’합니다.
만약 구글이 작정하고 고성능 AI 검색을 전면 무료화한다면? 비싼 클라우드 비용을 내야 하는 경쟁사들은 말라 죽을 수밖에 없습니다. 게다가 크롬, 안드로이드, 지메일로 연결된 생태계는 사용자가 굳이 새로운 앱을 깔 필요가 없게 만듭니다.
📝 [글의 핵심 요약]
- 착시 현상: 구글의 점유율 하락은 일시적이며, 내부에서는 강력한 반격을 준비 중입니다.
- 하드웨어 초격차 (TPU): 범용 GPU 대신 AI 연산에 특화된 TPU와 시스톨릭 배열 기술로 압도적인 효율을 달성했습니다.
- 알고리즘 혁명 (MDLM): 타자기처럼 느린 기존 방식 대신, 판화처럼 한 번에 답변을 생성하는 기술로 속도를 7배 높였습니다.
- 데이터의 깊이: 25년간 축적된 롱테일 데이터는 스타트업이 흉내 낼 수 없는 정확도를 보장합니다.
❓ 자주 묻는 질문
Q: 그래도 요즘은 챗GPT나 퍼플렉시티가 더 편하지 않나요?
A: 현재 사용자 경험(UX) 측면에서는 대화형 AI가 편할 수 있습니다. 하지만 구글이 이 새로운 UX를 자사 검색 엔진에 본격적으로 통합하고(Search Generative Experience), 속도 문제까지 해결한다면 편의성 격차는 순식간에 좁혀질 것입니다.
Q: 구글의 이런 기술들은 언제 우리가 써볼 수 있나요?
A: 이미 'AI 오버뷰' 등의 이름으로 검색 결과 상단에 적용되고 있습니다. MDLM 같은 차세대 기술은 '제미나이' 업데이트를 통해 순차적으로, 하지만 매우 빠르게 우리 일상에 스며들 것입니다.
구글이라는 거인은 잠들었던 것이 아니라, 더 높이 도약하기 위해 잠시 웅크리고 있었을 뿐인지도 모릅니다. 검색창이라는 껍질을 깨고, 전 세계의 데이터를 학습한 ‘초고속 인공지능 비서’로 재탄생할 구글. 혁명은 소리 없이, 하지만 가장 강력하게 우리의 일상을 파고들 것입니다.
당신은 지금 '타자기'를 쓰는 검색 엔진에 머무르시겠습니까, 아니면 '판화'를 찍어내는 미래의 속도에 올라타시겠습니까?
phoue.co.kr 에 가시면 더 자세한 이야기를 볼 수 있습니다.
'아는게 힘이다 > 과학, 공학' 카테고리의 다른 글
| 5,000억 달러짜리 도박: OpenAI가 그리는 2025년 미래 시나리오 (11) | 2025.12.01 |
|---|---|
| 소크라테스부터 자율주행 AI까지: 당신이 주목해야 할 에듀테크 (3) | 2025.12.01 |
| 넷플릭스 vs 통신사: 속도계 하나로 판을 뒤집는 법 (2) | 2025.11.28 |
| 삼성의 온디바이스 AI와 팔란티어의 AIP: 지식 그래프가 바꾸는 미래 (8) | 2025.11.24 |
| 클라우드플레어 vs AI 봇 전쟁의 서막 내 데이터도 돈이 된다? (4) | 2025.11.24 |



