지금까지 당연하게 누려왔던 '공짜 인터넷' 세상이 챗GPT와 같은 AI의 등장으로 급격히 변화하고 있습니다. HTTP 402의 부활부터 데이터 전쟁까지, 웹의 미래를 심층 분석합니다.
무료 인터넷의 종말: AI가 바꾼 웹의 규칙과 HTTP 402의 부활
안녕하세요! 오늘은 조금 무겁지만, 우리가 매일 사용하는 인터넷 공간에서 벌어지고 있는 아주 거대한 변화에 대해 이야기해 보려 합니다.
혹시 2025년 7월 1일이 어떤 날로 기록될지 상상해 보셨나요? 아마도 역사책은 이날을 '인터넷의 문이 잠긴 날'로 기억할지도 모릅니다. 지난 30년 가까이 우리는 인터넷을 마치 공기나 물처럼, 당연히 주어지는 무료 공공재로 여겨왔습니다. 검색창에 단어를 치면 정보가 쏟아지고, 블로그에 글을 쓰면 누군가 읽어주는 평화로운 세상이었죠.
하지만 단언컨대, 그 '낭만적인 무료 인터넷'의 시대는 끝났습니다. 그 이유가 무엇인지, 그리고 앞으로 우리의 웹 생활은 어떻게 바뀔지 지금부터 자세히 파헤쳐 보겠습니다.
신뢰의 붕괴와 '제로 클릭'의 시대 🧩
과거의 웹은 일종의 '암묵적인 계약'으로 유지되었습니다. "당신이 좋은 정보를 올리면, 검색 엔진이 사람들을 보내주겠다"는 약속이었죠. 하지만 생성형 AI가 등장하면서 이 약속은 휴지 조각이 되었습니다.

챗GPT나 Gemini 같은 AI들은 정보를 읽어가기만 할 뿐, 원작자의 웹사이트로 사람을 보내주지 않습니다. 사용자가 검색 결과 페이지에서 답만 얻고 떠나버리는 '제로 클릭(Zero-click)' 시대가 열린 것입니다.
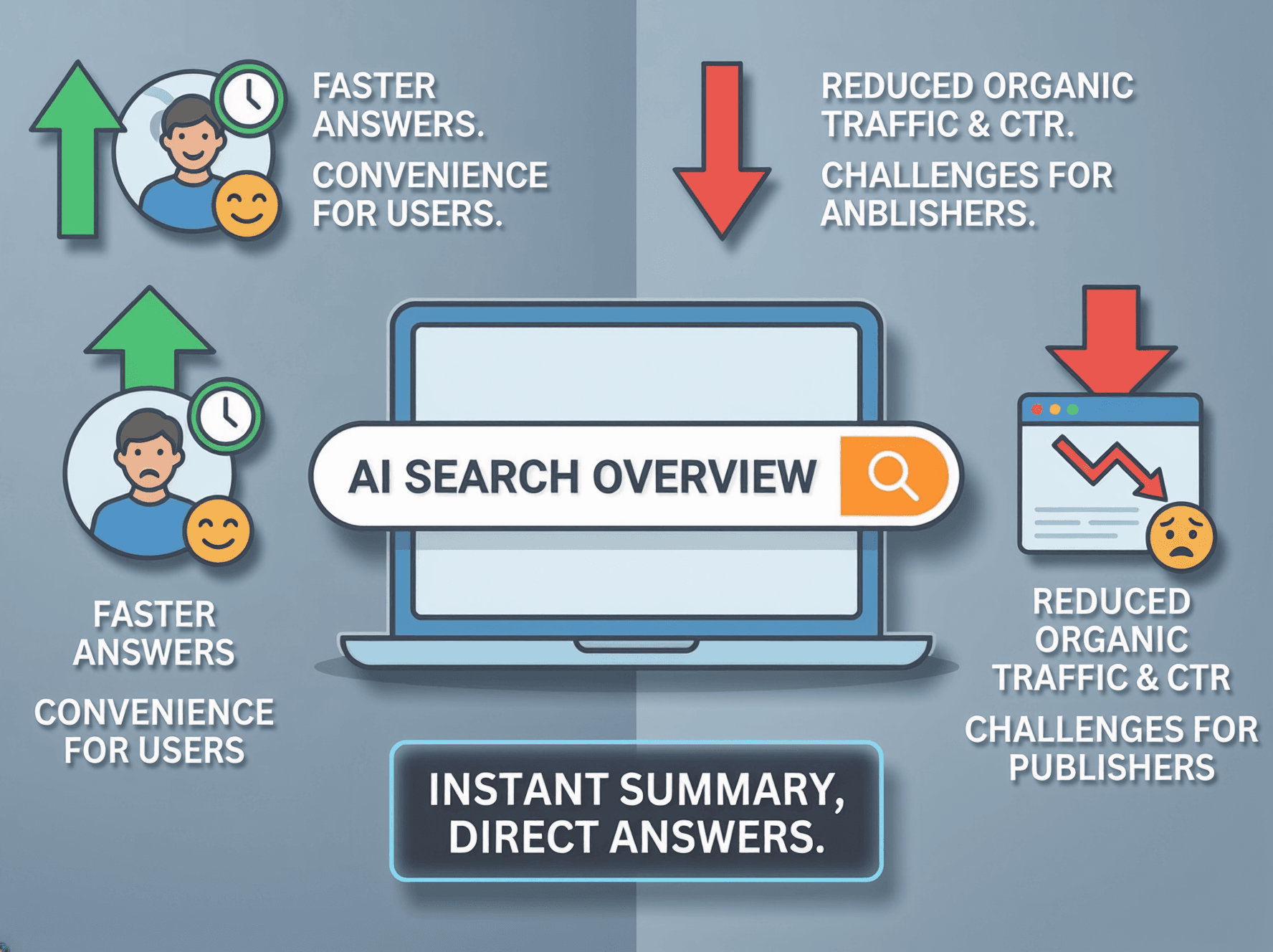
결국 기생충이 숙주를 잠식하는 것을 막기 위해, 웹의 수호자들은 거대한 성벽을 쌓기 시작했습니다. 이것은 단순한 기술 트렌드가 아닌, 여러분이 남긴 글과 사진을 둘러싼 '제1차 디지털 자산 전쟁'의 시작입니다.
보이지 않는 전쟁: 인프라가 무기가 되다 🧩
지금 이 순간에도 웹의 뒷단(Back-end)에서는 치열한 전투가 벌어지고 있습니다. 전 세계 웹 트래픽을 관리하는 클라우드플레어(Cloudflare)가 AI 봇들과의 전면전을 선포했기 때문입니다.
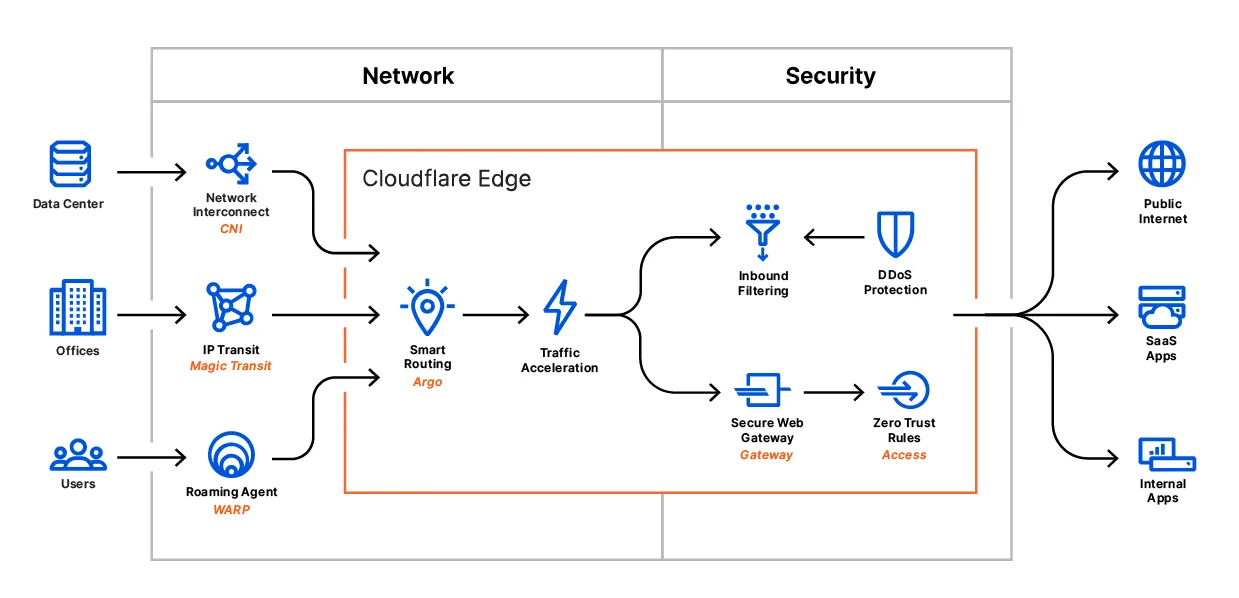
1. 신사협정의 파기: Robots.txt의 무력화
예전에는 robots.txt라는 파일에 "여기부터는 들어오지 마세요"라고 써 붙이면 검색 로봇들이 이를 지켰습니다. 하지만 데이터에 굶주린 AI 기업들은 이 낡은 팻말을 무시하고 담장을 넘기 시작했습니다.

이제 '정중한 요청'은 통하지 않습니다. 승인되지 않은 봇이 감지되면, 서버 근처에 가기도 전에 네트워크 가장자리에서 즉시 물리적으로 축출당하는 시대가 되었습니다.
2. 죽어있던 코드의 부활: HTTP 402
가장 충격적인 변화는 바로 '경제적 장벽'입니다. 여러분은 '404 Not Found'는 잘 아실 겁니다. 그런데 개발자들 사이에서 전설로만 전해지던 유령 코드가 무덤을 깨고 나왔습니다. 바로 HTTP 402 Payment Required (결제 필요)입니다.
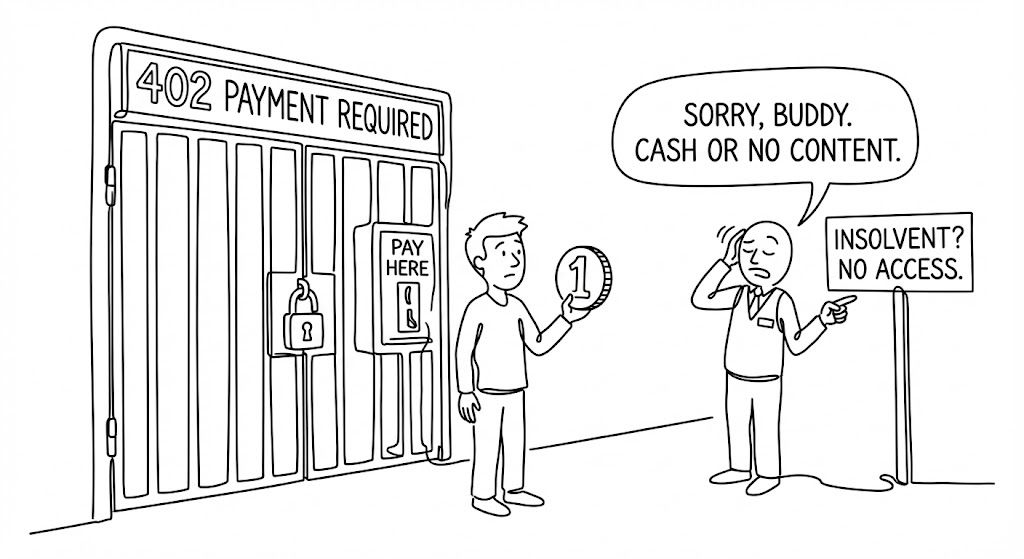
ℹ️ 알아두면 쓸모있는 지식
크롤링 건당 지불(Pay Per Crawl): AI 봇이 데이터를 요청하면, 시스템은 콘텐츠 대신 청구서를 날립니다. "이 데이터를 가져가려면 0.05달러를 내시오." 디지털 토큰으로 비용을 지불해야만 비로소 문이 열리는 것이죠.
3. 봇을 가두는 미궁: AI 라비린스
돈을 내지 않고 정보를 훔치려는 '도둑 봇'들을 위해 방어 시스템은 'AI 라비린스(Labyrinth)'를 가동합니다.
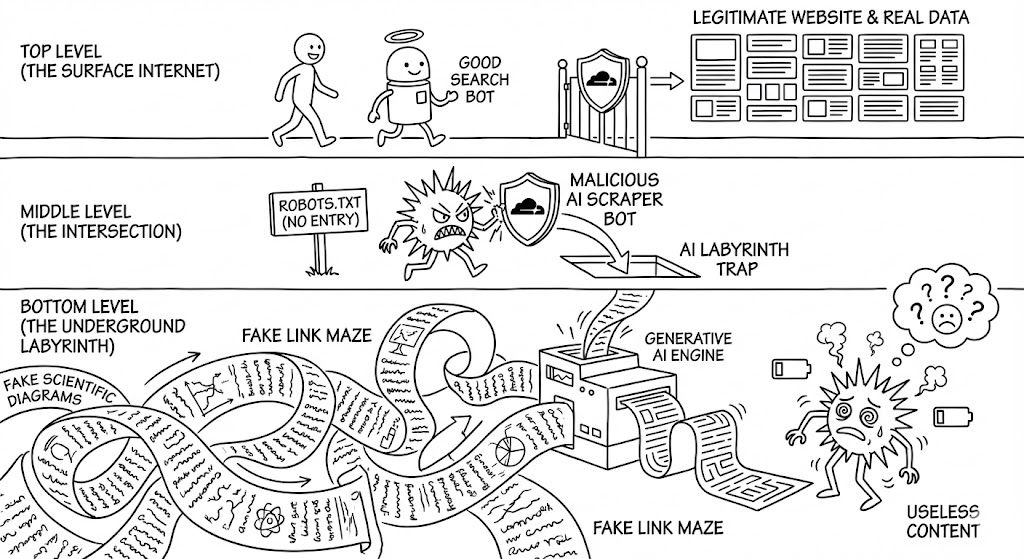
봇에게 가짜 링크를 흘리면, 봇은 그게 진짜 정보인 줄 알고 덥석 뭅니다. 하지만 그곳은 실시간으로 생성된 '아무 의미 없는 텍스트 덩어리'가 무한히 이어지는 타르 핏(Tar Pit, 끈적한 늪)입니다. 봇은 여기서 의미 없는 데이터를 수집하느라 막대한 전기세만 낭비하게 됩니다.
창과 방패: 기술적 군비 경쟁의 고도화 🧩
방어자가 문을 걸어 잠그면, 도둑은 열쇠 따는 기술을 배웁니다. 이제 단순한 차단을 넘어선 고도의 기술 경쟁이 시작되었습니다.
1. 디지털 지문(Fingerprint)의 대결: JA4
봇들은 1초마다 IP를 바꾸며 변장을 합니다. 그래서 방어자들은 JA4 핑거프린팅 기술을 사용합니다.

쉽게 말해 도둑이 옷을 바꿔 입어도 특유의 '걸음걸이'나 '숨소리'는 못 바꾼다는 점을 이용하는 겁니다. 통신 패턴을 분석해 "너는 겉모습은 크롬 브라우저지만, 속은 파이썬 스크립트구나!"라고 잡아내는 것이죠.
2. 픽셀 전쟁: 나이트셰이드(Nightshade)
데이터 자체에 독을 타는 기술도 등장했습니다. '나이트셰이드'는 이미지에 인간의 눈에는 보이지 않는 노이즈를 섞습니다.

이 그림을 AI가 학습하면 '고양이'를 '강아지'로, '핸드백'을 '토스트기'로 착각하게 됩니다. 결국 모델 전체가 망가지는 '모델 중독'을 유발하여, 창작자들이 자신의 작품을 지키기 위해 스스로 독을 뿌리는 아이러니한 상황이 벌어지고 있습니다.
경제적 붕괴와 스플린터넷의 도래 🧩
이 모든 전쟁의 근본 원인은 AI 데이터 시장이 '레몬 시장(Market for Lemons)'으로 변질되고 있기 때문입니다.

모델 붕괴(Model Collapse): AI의 근친교배
AI가 만든 데이터를 또 다른 AI가 학습하면 어떻게 될까요? 마치 생물학적 근친교배처럼 다양성이 사라지고 멍청해집니다. 이를 '모델 붕괴'라고 합니다.
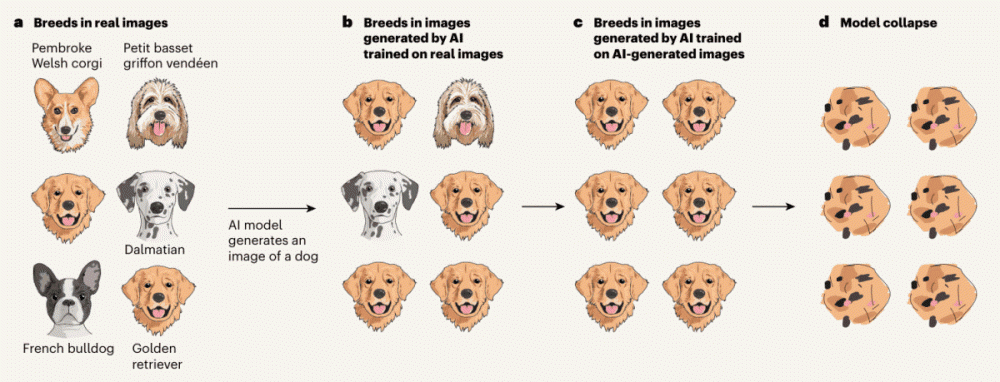
💡 흥미로운 사실: 이 때문에 2023년 이전, 즉 생성형 AI가 폭발하기 전에 사람이 작성한 '빈티지 데이터(Vintage Data)'의 가격이 천정부지로 치솟고 있습니다. 오염되지 않은 순수한 '인간의 데이터'가 귀해진 것이죠.
스플린터넷(Splinternet): 조각난 인터넷
이제 인터넷은 국가별 규제에 따라 산산조각 나고 있습니다.

- 미국: 저작권 소송의 전쟁터 (NYT vs OpenAI)
- 유럽연합: 강력한 규제의 요새 (AI Act)
- 일본: 학습의 낙원 (저작권 면제)
미래 전망: 수렵 채집에서 농경 사회로 🧩
앞으로의 웹은 크게 두 가지로 나뉠 것입니다. AI가 만든 쓰레기 정보가 넘치는 '공공 웹'과, 검증된 고품질 정보가 있는 '금고 웹(The Vault)'입니다.



이 과정에서 '인간 증명(Proof of Personhood)'이 중요해집니다. "나는 봇이 아니라 피가 흐르는 진짜 인간입니다"를 증명해야만 양질의 인터넷 서비스를 이용할 수 있는 시대가 오는 것이죠.
글의 핵심 요약 📝
- 무료의 종말: AI의 무차별 데이터 수집으로 인해 '무료 인터넷' 시대가 끝나고 유료화 장벽이 세워지고 있습니다.
- HTTP 402의 부활: 웹사이트들은 AI 봇에게 데이터 접근료를 요구하는 'Pay per Crawl' 모델을 도입하기 시작했습니다.
- 기술 전쟁: 봇을 차단하려는 'AI 라비린스', 'JA4 핑거프린팅'과 뚫으려는 공격 기술이 맞붙고 있습니다.
- 데이터의 가치: 인간이 만든 순수 데이터(빈티지 데이터)의 가치가 급상승하며, 인터넷은 '정보의 농경 사회'로 진입했습니다.
자주 묻는 질문 ❓
Q: 앞으로 모든 인터넷 사이트가 유료가 되나요?
A: 모든 사이트가 그렇지는 않겠지만, 양질의 정보를 제공하는 전문 블로그나 뉴스 사이트는 유료화되거나 '인간 인증'을 요구할 가능성이 매우 높습니다. 반면, 일반적인 공공 웹은 AI가 만든 저품질 콘텐츠로 채워질 수 있습니다.
Q: 내 사진이나 글을 AI가 못 가져가게 할 수 있나요?
A: 현재로서는 완벽한 방법은 없지만, '나이트셰이드'와 같은 데이터 오염 도구를 사용하거나, 접근 차단 기술을 적용한 플랫폼을 이용하는 것이 대안이 될 수 있습니다.
우리는 그동안 인터넷이라는 숲에서 정보를 마음껏 따먹는 수렵 채집인이었습니다. 하지만 이제 숲에는 울타리가 쳐졌습니다. 정보를 경작하고, 관리하고, 정당한 값을 지불해야 하는 시대.
당신이 오늘 인터넷에 남긴 생각 한 조각의 가치는 과연 얼마일까요?
phoue.co.kr 에 가시면 더 자세한 이야기를 볼 수 있습니다.
'아는게 힘이다 > 과학, 공학' 카테고리의 다른 글
| 넷플릭스 vs 통신사: 속도계 하나로 판을 뒤집는 법 (2) | 2025.11.28 |
|---|---|
| 삼성의 온디바이스 AI와 팔란티어의 AIP: 지식 그래프가 바꾸는 미래 (8) | 2025.11.24 |
| 호모 데우스의 탄생: 내 머릿속에 슈퍼컴퓨터가 들어온다면 (4) | 2025.11.19 |
| 데이터가 왕이다: 2025년 자율주행 시장의 냉혹한 현실 (10) | 2025.11.14 |
| '창백한 푸른 점'에서 다시 생각하는 우리의 자리 (5) | 2025.11.10 |



